

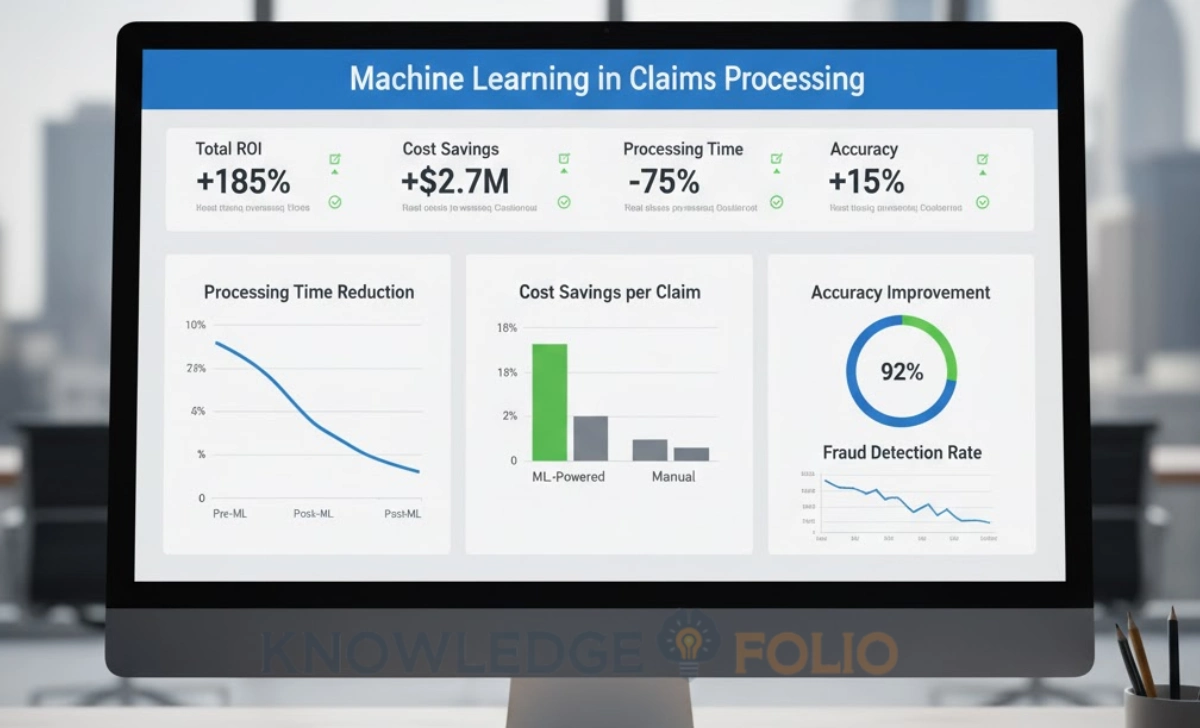
Machine learning in claims processing improves accuracy through automated document classification, computer vision for damage assessment, and predictive fraud detection. Real-world implementations show 30% reduction in processing time, 29% efficiency savings in damage assessment, and error rates below 21% using XGBoost models—while cutting loss-adjusting expenses by 20–25% through better fraud detection.
Claims processing remains one of the most operationally intensive and error-prone functions in insurance. Manual document review, inconsistent data entry, delayed fraud detection, and slow turnaround times create customer frustration while driving up costs. For insurance firms and analysts seeking competitive advantage, the question isn’t whether to adopt technology—it’s which technology delivers measurable accuracy improvements.
Machine learning in claims processing has moved beyond pilot programs into production deployment across leading insurers in 2024–25. Unlike rule-based automation that follows rigid scripts, ML models learn from historical data to recognise patterns, classify documents, assess damage, and flag anomalies with increasing sophistication. The results are compelling: faster processing, fewer errors, lower costs, and better customer experiences.
This article examines how insurers are applying machine learning across claims workflows, highlights concrete use cases with quantified results, and provides a practical framework for firms and analysts evaluating ML implementation. Whether you’re building internal capabilities or assessing vendor solutions, you’ll understand where ML delivers the highest impact and what infrastructure you need to succeed.
Why Claims Processing Needs Machine Learning Now
Traditional claims processing faces fundamental challenges that manual processes and simple automation can’t fully resolve. The volume and complexity of modern claims—combined with customer expectations for instant resolution—create operational pressure that human-only workflows struggle to manage efficiently.
Claims arrive in unstructured formats: emails, photos, PDFs, handwritten forms, medical records, police reports. Extracting relevant information requires human judgment, consuming hours per claim for adjusters who must review documents, verify coverage, assess damage, calculate settlements, and detect potential fraud. This manual effort introduces inconsistency and errors while creating processing bottlenecks.
Fraud adds another layer of complexity. Sophisticated fraudsters exploit the volume and time pressure of claims operations, knowing that manual reviews can’t catch subtle patterns. Traditional rule-based fraud detection generates high false-positive rates, flagging legitimate claims and frustrating customers. Meanwhile, actual fraudulent claims slip through undetected, costing insurers billions annually.
Key Challenges in Claims Workflows
Document handling represents a major pain point. Claims departments receive thousands of documents daily in inconsistent formats. Invoices, repair estimates, medical bills, incident reports, correspondence—each requires classification, data extraction, and routing to appropriate workflows. Manual document review is slow, expensive, and error-prone.
High volumes of low-value repetitive tasks consume adjuster time that could be spent on complex claims requiring human expertise. Simple data entry, coverage verification for straightforward claims, and routine damage assessment don’t require skilled adjusters—but in traditional workflows, they occupy significant capacity.
Fraud risk management with rule-based systems creates a dilemma. Set rules too strict and legitimate claims get flagged, delaying payouts and angering customers. Set rules too loose and fraud slips through. Static rules can’t adapt to evolving fraud tactics, requiring constant manual updates as fraudsters change methods.
Processing cycle times directly impact customer satisfaction. A claim that takes weeks to settle—even if ultimately paid fairly—generates negative experiences. Customers want fast, transparent resolution. Slow manual processes can’t meet these expectations at scale.
What Machine Learning Brings to the Table
Machine learning addresses these challenges through pattern recognition, predictive modelling, and continuous learning. Unlike rule-based systems programmed with fixed logic, ML models learn from historical claims data to identify complex relationships that humans might miss or that are too subtle for explicit rules.
Document classification and data extraction improve dramatically with ML. Computer vision and natural language processing can identify document types, extract key fields (dates, amounts, parties, injury descriptions), and route documents automatically—regardless of format variations. The models handle handwriting, poor image quality, and non-standard layouts that break traditional OCR systems.
Predictive modelling enables proactive claims management. ML models can predict claim severity, estimate settlement amounts, identify high-risk claims requiring expert review, and forecast processing times. This allows better resource allocation—routing simple claims to automated workflows while directing complex cases to experienced adjusters.
Anomaly detection for fraud operates differently than rule-based systems. ML models establish normal patterns from millions of claims, then flag deviations statistically likely to indicate fraud. They detect combinations of factors—timing, provider networks, claim characteristics, claimant history—that individually seem innocent but collectively suggest fraud. Research indicates ML increases throughput and accuracy in claims processing by learning from each case.

Core Use Cases of Machine Learning in Claims Processing
Understanding where ML delivers the most value helps prioritise implementation efforts. These use cases represent areas where insurers are achieving measurable results in 2024–25, backed by real-world case studies and quantified performance improvements.
Automated Document Ingestion and Classification
Claims documents arrive through multiple channels—email attachments, mobile app uploads, fax, postal mail, third-party systems. ML-powered document processing automatically classifies each document type (invoice, medical record, repair estimate, correspondence), extracts structured data, and routes to appropriate workflows without human intervention.
A Nordic insurer implemented AI-driven document automation across their claims operation in a project documented by major consultancies. The system ingests incoming documents regardless of format, identifies document types with over 95% accuracy, extracts key data fields, and updates claims files automatically. Previously, claims staff spent hours daily sorting documents and manually entering data.
The ML model handles variations that break traditional systems—handwritten notes on printed forms, poor-quality phone photos, documents in multiple languages, non-standard formats from different providers. Natural language processing extracts relevant information even from unstructured text like adjuster notes or customer correspondence.
Implementation results: Processing time for document-heavy claims dropped by approximately 40%. Data entry errors decreased significantly because ML extraction is more consistent than manual typing. Claims adjusters now spend time on analysis and decision-making rather than administrative tasks.
Technical approach: The implementation used supervised learning with convolutional neural networks for image-based documents and transformer models (BERT-family) for text extraction. The model was trained on over 100,000 historical claims documents with human-verified labels, then fine-tuned continuously with production feedback.
Visual Damage Assessment Using Computer Vision
Property and auto claims traditionally require physical inspections by adjusters or approved estimators. This creates delays (scheduling inspections, waiting for reports) and costs (adjuster time, travel expenses). Computer vision ML models can now assess damage from photos submitted by claimants, generating repair estimates with accuracy approaching human experts.
A major auto insurer deployed ML-powered damage assessment in a widely-studied implementation. Customers photograph vehicle damage using a mobile app, and the ML model analyses images to identify damaged parts, assess severity, and generate repair cost estimates. The system achieved 29% efficiency savings compared to traditional inspection processes.
The computer vision model recognises specific vehicle parts, distinguishes between superficial damage and structural issues, accounts for vehicle make and model in cost estimation, and flags cases requiring physical inspection due to complexity or ambiguity. This hybrid approach maintains quality while dramatically accelerating simple claims.
For property claims, similar systems assess roof damage, structural issues, or interior damage from photos or drone imagery. After natural disasters, insurers can prioritise claims by damage severity and deploy adjusters efficiently to the most complex cases while auto-processing straightforward claims.
Measurable outcomes: Average time from claim filing to estimate dropped from 3–5 days to under 2 hours for eligible claims. Customer satisfaction scores improved due to speed and transparency. Adjuster capacity increased as they focused on complex claims rather than routine damage assessment.
Technical considerations: The model requires training on diverse damage scenarios across vehicle types. Edge cases (exotic cars, unusual damage patterns, aftermarket parts) still require human review. Regular retraining prevents model drift as vehicle designs and repair costs evolve.
Fraud Detection and Predictive Loss-Leakage Modelling
Insurance fraud costs the global industry tens of billions annually. Traditional fraud detection relies on rule-based systems flagging obvious red flags—but sophisticated fraud involves subtle patterns across multiple claims or organised fraud rings where no single claim looks suspicious.
ML fraud detection analyses hundreds of variables simultaneously to identify anomalous patterns. Models consider claim characteristics (timing, amount, injury description), claimant history, provider networks, geographic patterns, and cross-reference against known fraud schemes. The system generates fraud probability scores, prioritising investigation resources on highest-risk claims.
Leading insurers have implemented ML fraud detection achieving significant reductions in loss-adjusting expenses. Industry analysis suggests improvements in the range of 20–25% decrease in fraud-related costs through better detection and deterrence. The models identify organised fraud rings by detecting shared providers, similar claim patterns, or timing correlations across apparently unrelated claims.
Predictive loss-leakage modelling extends beyond fraud to identify claims likely to settle for more than necessary due to inadequate documentation, missed subrogation opportunities, or inflated charges. ML models flag these claims early, prompting adjusters to gather additional evidence or negotiate more effectively.
Measurable Benefits of Machine Learning for Accuracy and Efficiency
Quantifying ML impact is essential for building business cases and measuring ROI. Leading implementations across the industry provide benchmarks for what insurers can realistically achieve with well-executed ML projects.
Processing Speed and Throughput Gains
Speed improvements from machine learning in claims processing are among the most visible benefits. Automated document handling, instant damage assessment, and faster fraud screening eliminate major bottlenecks in traditional workflows.
Industry data indicates that claims automation through ML reduces low-value manual work by approximately 30%. This doesn’t mean 30% fewer staff—it means adjusters handle 30% more claims or spend 30% more time on complex cases requiring expertise and judgment. The capacity increase allows insurers to manage volume growth without proportional headcount increases.
Straight-through processing rates improve dramatically. Simple claims that meet predefined criteria (low value, clear liability, standard damage patterns) can be approved automatically without human review. Leading insurers achieve straight-through processing on 20–40% of eligible claims, up from near zero with manual workflows.
Accuracy Improvements and Error Reduction
Accuracy matters as much as speed. Incorrect damage estimates, missed fraud, or data entry errors create rework, customer disputes, and financial leakage. ML systems demonstrate measurably better accuracy than manual processes in specific domains.
In health insurance claims prediction, ML models using gradient boosting algorithms achieved R-squared values around 79% in predicting high-cost claims—substantially better than traditional actuarial models. This allows more accurate reserving and proactive case management for complex medical claims.
Data extraction accuracy from unstructured documents reaches 95–98% with modern ML systems, compared to 85–90% for manual data entry by experienced staff. The consistency of ML (same document always produces same output) eliminates human variability from fatigue, distraction, or interpretation differences.
Fraud detection accuracy improves through reduced false positives and increased true positive rates. While traditional rule-based systems might flag 40% of legitimate claims for review (false positives), well-tuned ML models reduce this to 15–20% while catching more actual fraud. This balance is critical—excessive false positives waste investigation resources and anger customers, while missed fraud costs money.
Technical performance benchmarks:
- Document classification accuracy: 95–97% across major document types
- Damage assessment agreement with expert human estimators: 85–90% within 10% of human estimate
- Fraud detection: 70–75% precision (flagged claims actually fraudulent), 60–65% recall (actual fraud cases caught)
Cost Savings, Leak Reduction, and ROI
Financial benefits from ML in claims processing come through multiple channels: reduced staffing for manual tasks, lower fraud losses, faster settlements (reducing interest and storage costs), and improved subrogation recovery.
Industry analysis estimates a global opportunity exceeding $100 billion from generative AI and ML improvements in property and casualty claims handling. This reflects combined savings from fraud reduction, operational efficiency, better settlement accuracy, and enhanced customer retention.
Loss-adjusting expense (LAE) reductions of 20–25% are achievable through combined improvements in fraud detection, automated processing, and better resource allocation. For a mid-sized insurer with $500 million in annual claims and 15% LAE ratio, this translates to $15–19 million annual savings.
Fraud reduction alone generates substantial returns. If an insurer pays $1 billion annually in claims with an estimated 5% fraud rate, reducing fraud by even 20% saves $10 million per year. ML fraud detection systems typically cost $500K–2M for implementation and $200K–500K annually to operate—delivering ROI within the first year.
ROI considerations for implementation:
- Initial investment: $300K–3M depending on scope (single use case vs. comprehensive platform)
- Ongoing costs: $150K–600K annually (licensing, infrastructure, model maintenance)
- Payback period: Typically 12–24 months for well-selected use cases
- Ongoing benefits: Compound as models improve and additional use cases deploy
Implementation Considerations and Challenges for Insurers and Analysts
Successfully deploying ML in claims processing requires more than selecting algorithms—it demands careful attention to data infrastructure, governance frameworks, and organisational change management. Understanding common pitfalls helps avoid costly missteps.
Data and Model Readiness
ML models are only as good as the data they learn from. Claims data quality issues—incomplete records, inconsistent coding, missing labels, legacy system silos—directly limit model performance. Before investing in ML, audit your data landscape.
Data requirements for ML in claims:
- Volume: Minimum 10,000–50,000 historical claims for training, more for complex models
- Quality: Accurate, complete records with consistent data definitions across systems
- Labels: For supervised learning, you need verified outcomes (fraud/not fraud, actual vs. estimated cost)
- Diversity: Training data must represent the variety of claims you’ll process (claim types, geographies, scenarios)
- Recency: Recent data reflects current patterns; stale data produces outdated models
Integration with legacy systems poses technical challenges. Your ML models need to access policy data, claims history, customer information, and external data sources (weather, telematics, repair costs) in real time or near-real time. APIs and data pipelines must handle required volumes without creating performance bottlenecks.
Research emphasises that data quality and integration challenges often delay or derail ML projects more than algorithmic complexity. Insurers should allocate 40–60% of project effort to data preparation and integration, not model development.
Practical steps for data readiness:
- Conduct data quality assessment: completeness, accuracy, consistency across sources
- Establish data governance: ownership, definitions, quality standards, access controls
- Build data pipelines: automated extraction, transformation, loading from source systems
- Create labeled datasets: retrospectively label historical claims for supervised learning
- Plan for ongoing data management: continuous quality monitoring and improvement
Governance, Bias, Transparency, and Compliance
ML models in claims processing make decisions affecting customer outcomes and financial results. Governance frameworks ensure models operate fairly, transparently, and in compliance with regulations.
Bias risk is significant. If historical claims data reflects discriminatory practices (conscious or unconscious), ML models trained on that data will perpetuate the bias. Models might unfairly flag claims from certain demographics or underestimate legitimate damages. Australian regulators increasingly scrutinise algorithmic decision-making for fairness.
Model explainability matters for customer trust and regulatory compliance. “Black box” models that can’t explain why they declined a claim or adjusted an estimate create legal risk and undermine customer confidence. Regulations in multiple jurisdictions require insurers to explain automated decisions affecting customers.
Governance framework components:
- Model documentation: Architecture, training data, performance metrics, limitations, update history
- Bias testing: Regular audits for disparate impact across demographics, geographies, claim types
- Human oversight: Escalation procedures for edge cases, customer disputes, high-value claims
- Performance monitoring: Ongoing tracking of accuracy, bias metrics, model drift
- Audit trails: Complete logs of model decisions, inputs, versions for regulatory review
Regulatory compliance extends beyond fairness. Privacy regulations govern how you collect, use, and store customer data for ML training. Security requirements protect sensitive information. Insurance-specific regulations may mandate human review for certain decisions or require specific documentation.
Choosing the Right Use Case and Scaling
Not all ML projects deliver equal value. Prioritise use cases based on business impact, technical feasibility, and implementation risk. Starting with the wrong use case—too complex, insufficient data, or low business value—creates expensive failures that undermine future AI initiatives.
Use case selection criteria:
- Business impact: High volume or high cost per claim justifies investment
- Data availability: Sufficient quality data exists or can be created
- Technical complexity: Match project scope to your team’s ML maturity
- Regulatory risk: Lower-risk use cases (internal automation) before higher-risk (customer-facing decisions)
- Stakeholder support: Claims staff willing to adopt and provide feedback
Start with pilot projects demonstrating clear value within 3–6 months. A successful pilot on one claim type or region builds organizational confidence and provides lessons for scaling. Document what works, what doesn’t, and what infrastructure improvements are needed.
Scaling considerations: Moving from pilot to production requires different infrastructure—higher performance requirements, integration with more systems, formal change management processes, training for all staff, and support systems for troubleshooting. Plan scaling as a distinct project phase, not an automatic continuation of the pilot.
Implementation Checklist for ML in Claims Processing
Use this checklist to assess readiness and guide your ML implementation:
Data Infrastructure:
- [ ] Historical claims data volume sufficient for training (minimum 10K–50K records)
- [ ] Data quality assessed and improvement plan in place
- [ ] Integration with policy, claims, and external data sources established
- [ ] Labeled datasets created for supervised learning
- [ ] Data governance policies covering ML use, privacy, security
Technical Capabilities:
- [ ] ML talent available (in-house data scientists or trusted vendor partners)
- [ ] Infrastructure supports ML workloads (compute, storage, model serving)
- [ ] Model development and deployment pipelines established
- [ ] Performance monitoring and alerting systems in place
Governance and Compliance:
- [ ] Model risk management framework established
- [ ] Bias testing procedures defined and implemented
- [ ] Explainability requirements identified and addressed
- [ ] Regulatory compliance verified (privacy, insurance regulations)
- [ ] Human oversight processes for high-stakes decisions
Organisational Readiness:
- [ ] Executive sponsorship and budget secured
- [ ] Claims staff involved in use case selection and pilot design
- [ ] Training plan for staff working with ML systems
- [ ] Change management approach addresses concerns about automation
- [ ] Success metrics defined and measurement systems ready
Use Case Prioritisation:
- [ ] High-impact use cases identified based on volume and cost
- [ ] Technical feasibility assessed (data availability, complexity)
- [ ] Pilot scope defined with clear success criteria
- [ ] Scaling plan outlines expansion beyond pilot
Conclusion
Machine learning in claims processing has proven its value through measurable improvements in speed, accuracy, and cost efficiency. Leading insurers are achieving 30% reductions in manual work, 29% efficiency savings in damage assessment, and 20–25% decreases in loss-adjusting expenses through well-implemented ML solutions.
For insurance firms and analysts, success requires more than adopting technology—it demands careful attention to data quality, governance frameworks, appropriate use case selection, and organisational change management. The insurers realising the greatest benefits start with focused pilots on high-value use cases, build robust data and governance foundations, and scale systematically based on proven results.
Begin by assessing your data readiness and identifying your highest-impact pain point—whether document processing, damage assessment, or fraud detection. Pilot one use case with clear success metrics and a defined timeline. Build governance frameworks from day one, not as an afterthought. Scale only after proving value and learning what infrastructure investments are needed.
Call to Action: Ready to improve claims accuracy with machine learning? Start with the implementation checklist above, assemble a cross-functional team, and pilot a high-impact use case. Have experience deploying ML in claims or questions about getting started? Share your insights in the comments—the insurance industry advances fastest when we learn from each other’s successes and challenges.

